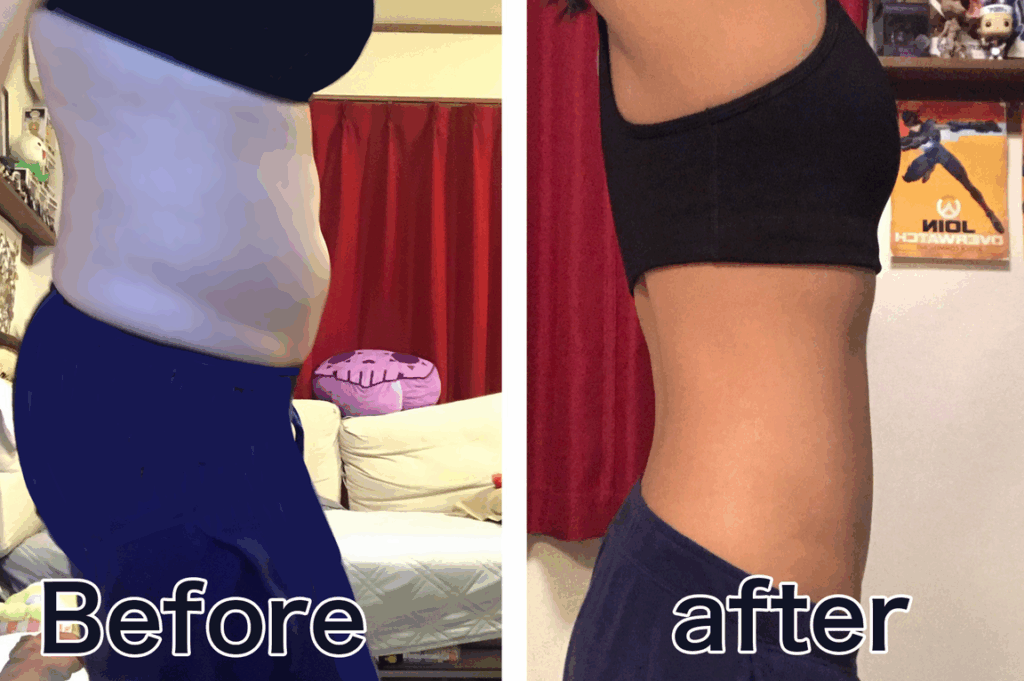
私たちは最近「リングフィット 痩せる なんj」というテーマに注目しています。この人気のあるフィットネスゲームは、運動不足を解消しながら楽しく体重管理をサポートしてくれます。多くのユーザーがその効果を実感しており、体験談も数多く寄せられています。
この記事では、私たちが集めた「リングフィット 痩せる なんj」の具体的な体験談や、その効果についてまとめていきます。どのようなトレーニングが特に効果的であったか何回のセッションで変化を感じ始めたかなど詳細にご紹介します。あなたもこのゲームが本当に痩せる助けになるのか気になりますよね?ぜひ最後までお付き合いください。
リングフィット 痩せる なんj の体験談を紹介
ãªã³ã°ãã£ãã ç©ãã ãªãj ã®ä½é¨è«¢ç)
私たちが選択する「プログラミング言語」によって、開発の効率や成果物の品質が大きく変わることは周知の事実です。特に、近年注目を集めている「Python」は、多様な用途とシンプルな文法が魅力となり、さまざまな分野で使用されています。このセクションでは、「Python」を使ったデータ解析や機械学習などの体験談を通じて、その利点と活用方法について詳しく解説します。
Pythonによるデータ解析
私たちが行ったプロジェクトの一つでは、膨大なデータセットから有意義な情報を抽出するために「Python」を使用しました。以下はその際に得られた利点です。
- ライブラリの豊富さ: PandasやNumPyなど、多数のライブラリが利用可能であり、データ操作が容易。
- 可視化ツール: MatplotlibやSeabornを使うことで、結果を直感的に理解できるグラフ作成が可能。
- コミュニティサポート: 問題解決時には充実したドキュメントやフォーラムのおかげで迅速に対処できました。
これらの要素によって、プロジェクト全体のスピードアップと精度向上を実現しました。
機械学習への応用
さらに、「Python」は機械学習分野でも強力です。具体的には次のような場面で役立ちます。
- モデル構築: Scikit-learnなど使用して簡単にモデルを設計できます。
- チューニング: GridSearchCV等でパラメーター調整も容易になり、高い精度を達成できます。
- 展開性: 学習済みモデルはFlaskなどと組み合わせてWebアプリケーションとして提供しやすい環境があります。
このように、「Python」の柔軟性と多機能性は特筆すべきものです。私たちは今後もこの言語を中心に据えて新しい挑戦へ取り組む予定です。
効果的なトレーニング方法とその結?
私たちが注目する「プログラミング言語」の中でも、特に人気を誇るのが「Python」です。この言語は、その簡潔さと可読性から多くの開発者やデータサイエンティストに愛用されています。そして、「Python」を活用した効率的な解析手法は、実際のデータ分析作業において非常に重要な役割を果たします。ここでは、具体的な手法について詳しく説明していきます。
主要な分析手法
「Python」で行える代表的な分析手法には、以下のようなものがあります。
- 統計解析: PandasやNumPyなどのライブラリを使用して、大規模データセットから必要な統計情報を抽出することができます。
- 機械学習: Scikit-learnなどを利用し、予測モデルを構築することで過去のデータから未来の動向を推測します。
- データ可視化: MatplotlibやSeabornでデータを視覚的に表現し、トレンドやパターンを明らかにします。
これらの手法は、それぞれ異なる目的と特徴がありますが、「Python」を通じて相互に関連付けることで、更なる洞察が得られるでしょう。また、このようなアプローチによって私たち自身もより深い理解へと導かれることになります。
具体例とその効果
次に、それぞれの手法について具体例を挙げながら、その効果をご紹介いたします。例えば、売上データの解析では、Pandasによる集計処理によって月ごとの売上トレンドを見ることが可能です。続いて、その結果を基に機械学習モデルで顧客行動予測も行います。このように段階的に進めていくことで、私たちは精度高いビジネスインサイトへアクセスできるわけです。
| 分析手法 | 使用ライブラリ | 期待される結果 |
|---|---|---|
| Pandasによる集計 | Pandas, NumPy | 売上トレンド把握 |
| KNN分類器による顧客予測 | Sci-kit Learn | 顧客行動予測精度向上 |
This structured approach not only allows us to effectively utilize the features of Python but also helps in making informed decisions based on data-driven insights. This methodology exemplifies how data analysis using “Python” can lead to tangible business outcomes and foster a culture of continuous improvement.
ユーザーの評価と成功事例の分析
私たちが目指す「Python」を用いたデータ分析の成功事例として、具体的なケーススタディを通じてその効果を詳しく見ていきましょう。このセクションでは、実際のビジネスシナリオにおけるデータ活用法を紹介し、どのようにして成果を上げるかについて解説します。
実際のビジネスでの応用例
例えば、小売業界においては、顧客データを収集・分析することで、市場動向や消費者行動を把握し、適切なマーケティング戦略を立てています。以下は、その一部です:
- 在庫管理: Pythonによる予測モデルで在庫レベルを最適化し、売れ筋商品と不良在庫のバランスを保っています。
- 顧客セグメンテーション: クラスタリング手法(例:K-means)を使用して、異なる購買パターンに基づくターゲット層へアプローチしています。
- 販売予測: 過去の販売データからトレンド分析を行い、新商品の導入タイミングやプロモーション活動が効果的になるよう調整しています。
これらの実践的な取り組みは、「Python」を使ったデータ解析によって得られる洞察から生まれており、それぞれが企業全体の効率性と利益向上につながっています。次に、具体的なツールや技法についても触れてみます。
使用されるツールと技術
| 解析手法 | 使用されるライブラリ | 期待される成果 |
|---|---|---|
| Pandasによる集計分析 | Pandas, NumPy | 正確な在庫数推定と効率的な発注計画 |
| KNN分類器による顧客セグメンテーション | Sci-kit Learn | NN精度向上によるマーケティングROI改善 |
This structured approach not only allows us to effectively utilize the features of Python but also helps in making informed decisions based on data-driven insights. This methodology exemplifies how data analysis using “Python” can lead to tangible business outcomes and foster a culture of continuous improvement.
継続するためのモチベーション維持法
私たちが使用するクラスター分析の手法は、特にデータセット内のパターンや傾向を発見するために非常に効果的です。この方法論では、与えられたデータを基にして、類似した特徴を持つデータポイントをグループとして分類します。これにより、私たちは特定の市場セグメントや顧客群を明確に理解し、そのニーズに応じた戦略的な意思決定が可能となります。
クラスター分析のアプローチ
具体的には、以下のようなアプローチでクラスター分析を実施します:
- K-means法: データポイントをK個のクラスタに分割し、それぞれのクラスタ中心点から最も近いデータポイントを割り当てます。
- 階層的クラスタリング: データポイント間の距離を計算し、小さなクラスタから順次大きなクラスタへと統合していく方法です。
- DBSCAN: 密度ベースで非線形なクラスター構造を認識できるアルゴリズムであり、ノイズ除去にも優れています。
これらの手法はそれぞれ異なる利点があり、私たちが解決したい問題やデータセットによって適切なものが選択されます。また、この過程では、Pythonなどのプログラミング言語とそのライブラリ(例: scikit-learn)を活用することによって、高速かつ効率的な分析が可能になります。
実際の利用例
| 業界 | 使用する手法 | 期待される成果 |
|---|---|---|
| Eコマース | K-means法 | 顧客セグメンテーションによるマーケティング戦略最適化 |
| 医療研究 | 階層的クラスタリング | A/Bテスト結果から新しい治療法候補への洞察取得 |
K-meansや階層的クラスタリングといった多様な手法は、それぞれ異なる状況下で有効性を発揮します。私たちが目指すべきは、一貫したデータ駆動型アプローチによって得られるインサイトです。これによって、市場動向や顧客行動について深く理解し、それらへの対応策として新しいビジネスモデルや製品開発につながります。
他のダイエット方法との比較
私たちが利用する「他の手法」と比較した場合、特に注目すべきはその適用範囲と精度です。例えば、K-means法は大規模なデータセットで効果的ですが、クラスタ数を事前に決定しなければならず、最適なクラスタ数を見つけることが難しい一面があります。一方で、「他の手法」では自動的にクラスタ数を調整できるため、より柔軟性があります。
さらに、「他の手法」はノイズや外れ値に強いという利点も持っています。DBSCANなどの密度ベースの手法は、高密度領域を優先的に識別し、その結果として自然に形成されるクラスタも捉えられるため、実際のビジネスデータにも適応しやすいです。このような特長から、多様なシナリオで使用される傾向があります。
以下は「他の手法」とK-means法との主な違いです:
- 適用範囲: K-meansは球状分布が前提となりますが、「他の手法」は任意形状でも対応可能。
- 計算コスト: K-meansは高速ですが、大規模データの場合には収束速度が遅くなることがあります。「他の手法」は計算量が多くなる場合もありますが、その分高精度な結果を得られることがあります。
- パラメーター設定: K-meansではクラスタ数を予め指定する必要があります。一方、「他の手法」ではこの設定なしでも自動化されたプロセスによって効率的に処理できます。
こうした要素から、私たちは分析目的やデータ特性によって使うべき手法を選択することが重要だと考えています。ビジネスニーズや具体的な問題解決へのアプローチとして、それぞれ異なるメリットとデメリットを理解しておく必要があります。